说说对 CSS 工程化的理解
CSS 工程化是为了解决以下问题:
- 宏观设计:CSS 代码如何组织、如何拆分、模块结构怎样设计?
- 编码优化:怎样写出更好的 CSS?
- 构建:如何处理我的 CSS,才能让它的打包结果最优?
- 可维护性:代码写完了,如何最小化它后续的变更成本?如何确保任何一个同事都能轻松接手?
以下三个方向都是时下比较流行的、普适性非常好的 CSS 工程化实践:
- 预处理器:Less、 Sass 等;
- 重要的工程化插件: PostCss;
- Webpack loader 等 。
基于这三个方向,可以衍生出一些具有典型意义的子问题,这里我们逐个来看:
(1)预处理器:为什么要用预处理器?它的出现是为了解决什么问题?
预处理器,其实就是 CSS 世界的“轮子”。预处理器支持我们写一种类似 CSS、但实际并不是 CSS 的语言,然后把它编译成 CSS 代码:
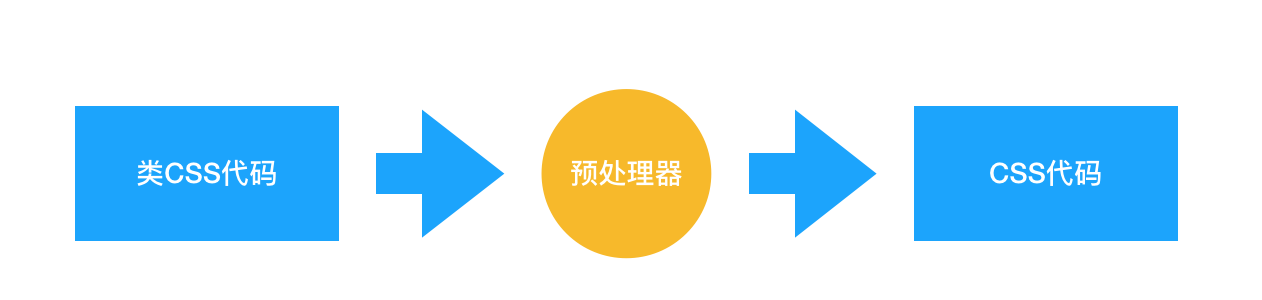
那为什么写 CSS 代码写得好好的,偏偏要转去写“类 CSS”呢?这就和本来用 JS 也可以实现所有功能,但最后却写 React 的 jsx 或者 Vue 的模板语法一样。
随着前端业务复杂度的提高,前端工程中对 CSS 提出了以下的诉求:
- 宏观设计上:我们希望能优化 CSS 文件的目录结构,对现有的 CSS 文件实现复用;
- 编码优化上:我们希望能写出结构清晰、简明易懂的 CSS,需要它具有一目了然的嵌套层级关系,而不是无差别的一铺到底写法;我们希望它具有变量特征、计算能力、循环能力等等更强的可编程性,这样我们可以少写一些无用的代码;
- 可维护性上:更强的可编程性意味着更优质的代码结构,实现复用意味着更简单的目录结构和更强的拓展能力,这两点如果能做到,自然会带来更强的可维护性。
这三点是传统 CSS 所做不到的,也正是预处理器所解决掉的问题。预处理器普遍会具备这样的特性:
- 嵌套代码的能力,通过嵌套来反映不同 css 属性之间的层级关系 ;
- 支持定义 css 变量;
- 提供计算函数;
- 允许对代码片段进行 extend 和 mixin;
- 支持循环语句的使用;
- 支持将 CSS 文件模块化,实现复用。
(2)PostCss:PostCss 是如何工作的?我们在什么场景下会使用 PostCss?
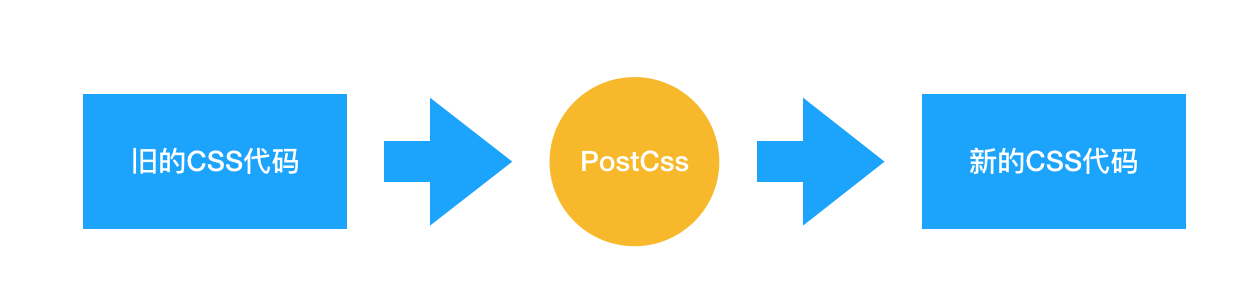
它和预处理器的不同就在于,预处理器处理的是 类CSS,而 PostCss 处理的就是 CSS 本身。Babel 可以将高版本的 JS 代码转换为低版本的 JS 代码。PostCss 做的是类似的事情:它可以编译尚未被浏览器广泛支持的先进的 CSS 语法,还可以自动为一些需要额外兼容的语法增加前缀。更强的是,由于 PostCss 有着强大的插件机制,支持各种各样的扩展,极大地强化了 CSS 的能力。
PostCss 在业务中的使用场景非常多:
- 提高 CSS 代码的可读性:PostCss 其实可以做类似预处理器能做的工作;
- 当我们的 CSS 代码需要适配低版本浏览器时,PostCss 的 Autoprefixer 插件可以帮助我们自动增加浏览器前缀;
- 允许我们编写面向未来的 CSS:PostCss 能够帮助我们编译 CSS next 代码;
(3)Webpack 能处理 CSS 吗?如何实现?
- Webpack 在裸奔的状态下,是不能处理 CSS 的,Webpack 本身是一个面向 JavaScript 且只能处理 JavaScript 代码的模块化打包工具;
- Webpack 在 loader 的辅助下,是可以处理 CSS 的。
如何用 Webpack 实现对 CSS 的处理:
- Webpack 中操作 CSS 需要使用的两个关键的 loader:css-loader 和 style-loader
- 注意,答出“用什么”有时候可能还不够,面试官会怀疑你是不是在背答案,所以你还需要了解每个 loader 都做了什么事情:
- css-loader:导入 CSS 模块,对 CSS 代码进行编译处理;
- style-loader:创建style标签,把 CSS 内容写入标签。
在实际使用中,css-loader 的执行顺序一定要安排在 style-loader 的前面。因为只有完成了编译过程,才可以对 css 代码进行插入;若提前插入了未编译的代码,那么 webpack 是无法理解这坨东西的,它会无情报错。